UTF-8 has been the predominant character encoding system for the world-wide web since 2009 and as of October 2018 accounts for over 90% of all web pages. As of October 2018, UTF-8 is not supported by Microsoft SQL Server.
SQL Server 2019 will remedy this situation, as current SQL Server community technology previews illustrate. The one- and two-byte character datatypes of SQL Server do not change; UTF-8 is implemented as a new collation, and this new option must be enabled during installation when one is setting the value for the server's default collation. Briefly, the idea behind UTF-8 is that classic 7-bit ASCII codes are not changed and are directly compatible. That is to say, a UTF-8 document containing only ASCII characters would be identical to a classic ASCII document. However, additional characters beyond ASCII are defined using 2, 3, or 4 bytes. This makes UTF-8 particularly valuable for documents which contain a small number of non-ASCII characters embedded in a largely ASCII document.
As is the case with all collations, you can assign a server default and then assign specific collations to databases, tables, columns, and individual queries.
Let's start with a simple SELECT statement with a literal character string:
SELECT 'Traditional: Zhong Guo Modern: Zhong Guo '
The most important thing to notice about this query is what's not there! There's no "N" since this string is not a two-byte-per-character Unicode string.
Now let's take a look at the savings provided by UTF-8.
DECLARE @S VARCHAR(8000) = 'These are the traditional characters for the word for ''China'': Zhong Guo '
PRINT @S
PRINT DATALENGTH(@S)
PRINT LEN(@S)
LEN( ) gives us the number of characters in the string, 65. Expressing this string in Unicode would require 130 bytes. DATALENGTH( ) tells us that the actual number of bytes required by UTF-8 is only 69.
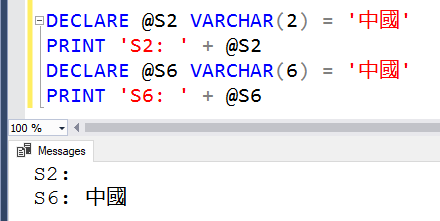
We do have to be a bit more careful, though, when counting characters. The classic VARCHAR declaration as the number of characters won't work.
The declaration must be at least as large as the number of bytes in the string, not the number of characters in the string.

Conclusion
UTF-8 provides a new alternative to Unicode for organizations that must mix a few foreign characters in largely ASCII documents. Since many characters take up more space in UTF-8 than in Unicode, the indiscriminate use of UTF-8 for documents containing many foreign characters would actually be worse than using Unicode datatypes. But the savings in memory and disk space resulting from the appropriate use of UTF-8 can be substantial
Related Training:
SQL Server Training
