User-defined scalar functions (scalar UDFs) provide SQL Server developers with an excellent means to organizer and re-use code. Unfortunately, these benefits often come at the price of poor, and in many cases horrendous, performance.
Froid is a technology arising from Microsoft Research that addresses these performance problems with novel optimization techniques. In SQL Server 2019, this optimization can be observed in the execution of scalar functions that execute database queries as a part of their functionality.
The Problem
Since the introduction of SQL Server user-defined scalar functions, the query optimizer has simply invoked the functions without considering what the functions actually do. If a SELECT statement containing a UDF returns a thousand rows, the function code is likely to execute a thousand times. If the function code executes its own SELECT statement, this statement may also execute a thousand times, even when once might be sufficient in an appropriately optimized query. The word quickly went out: "Never access the database from within scalar UDF code!"
Enter Froid
In SQL Server 2019, Froid technology is applied to this problem with great benefit. Let's explore a query using the Learning Tree "Bigwind" database, which has the same table structure as Microsoft's class Northwind, but which was designed to illustrate poor performance. We'll start by creating a scalar UDF that accesses a database.
/*****************************************************************/
SET STATISTICS IO ON
SET STATISTICS TIME ON
/*****************************************************************/
GO
CREATE FUNCTION OrderTotal(@OrderID INT)
Returns Money
AS
BEGIN
DECLARE @Total MONEY
SELECT @Total = CAST(SUM(UnitPrice * Quantity * (1 - Discount))AS MONEY) FROM [Order Details]
WHERE OrderID = @OrderID
RETURN @Total
END
GO
Here we have a query that uses the scalar UDF.
SELECT OrderID, OrderDate, dbo.OrderTotal(OrderID) FROM Orders
Here we have a query that returns the same rows, but obtains the desired results using a join rather than calling the UDF.
SELECT o.OrderID, o.OrderDate,
CAST(SUM(UnitPrice * Quantity * (1 - Discount))AS MONEY)
FROM [Order Details] od
RIGHT JOIN Orders o
ON o.OrderID = od.OrderID
GROUP BY o.OrderID, o.OrderDate
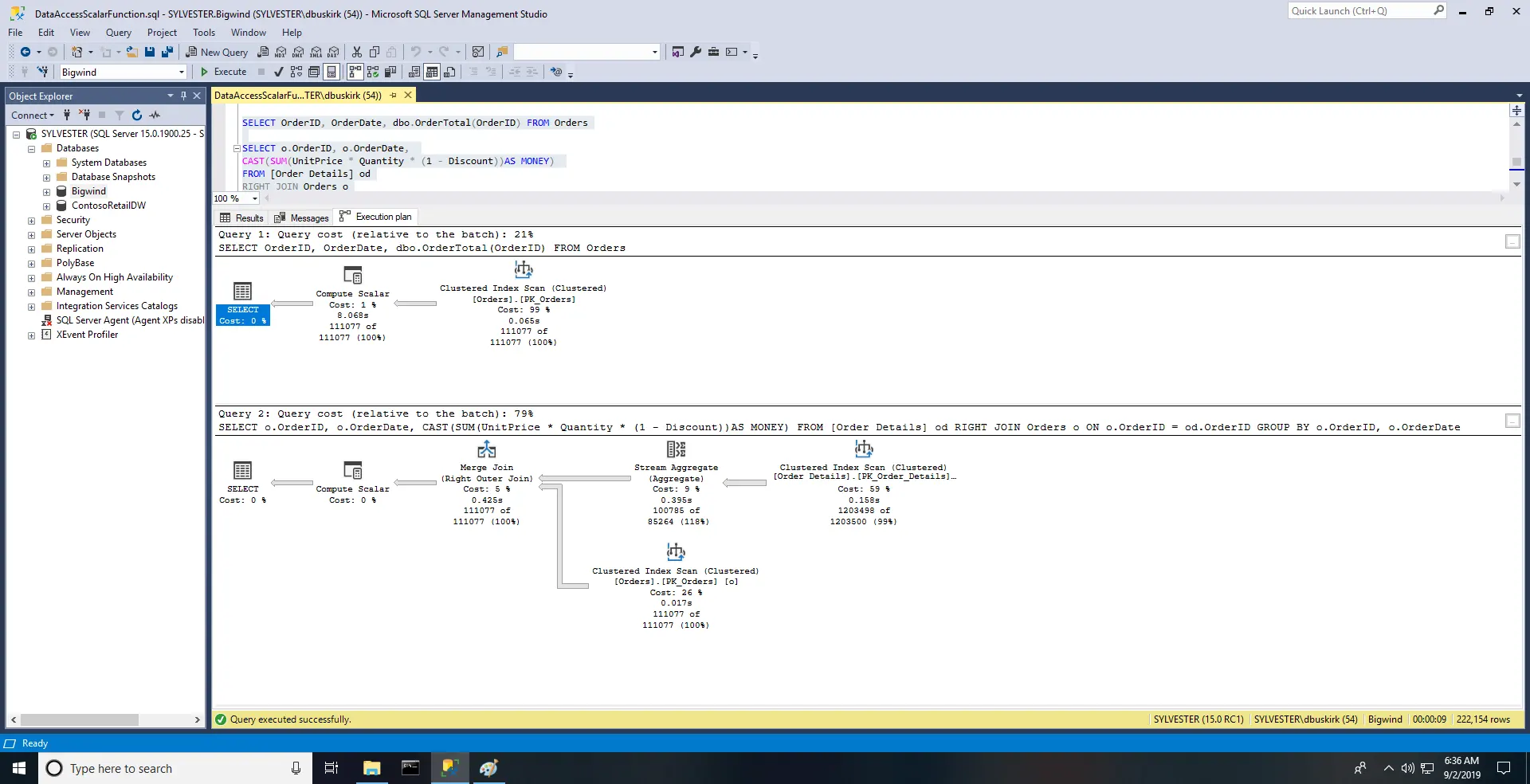
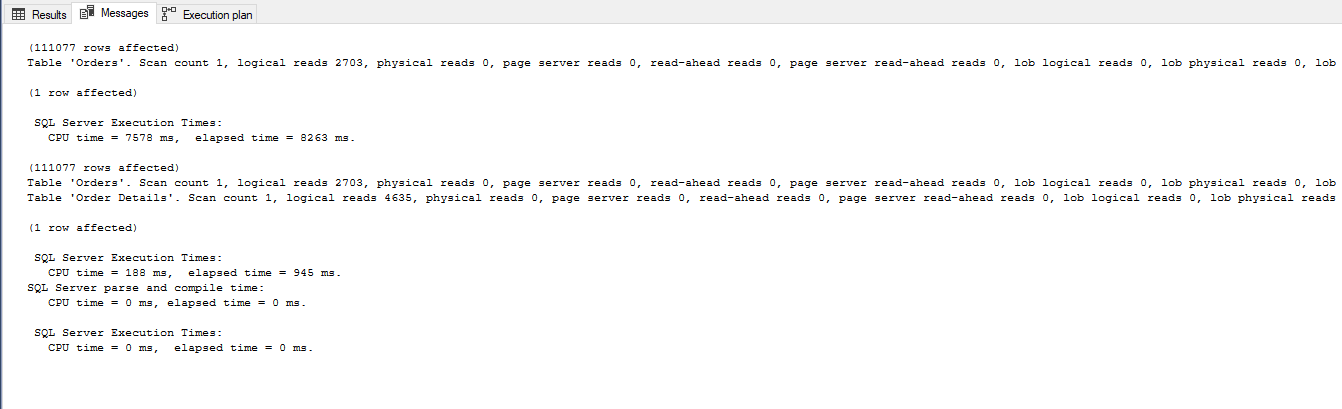
When we run these two queries together using compatibility level 140, i.e. SQL Server 2017, most indications are that the UDF is better. The estimated cost is lower and STATISTICS IO reports fewer page reads. But this is an illusion. Since the optimizer does not notice the SELECT statement in the UDF, the page reads and the executed cost are not only wrong, they are very wrong. The execution time provides incontrovertible evidence: the query calling the UDF took 8263 ms in this test, compared with 945 ms for the conventional JOIN.
We can run the same test again after adjusting the compatibility level to 150 (SQL Server 2019). The astute reader will notice subtle changes in the query plan for the UDF query. Curiously, excessive logical reads are reported, but the roughly ten-fold improvement in performance can be readily noticed by a human without a stopwatch. If you want a number, in this test was 958 milliseconds for the UDF and 892 milliseconds for the classic JOIN. Of course, measured times will vary with each execution.
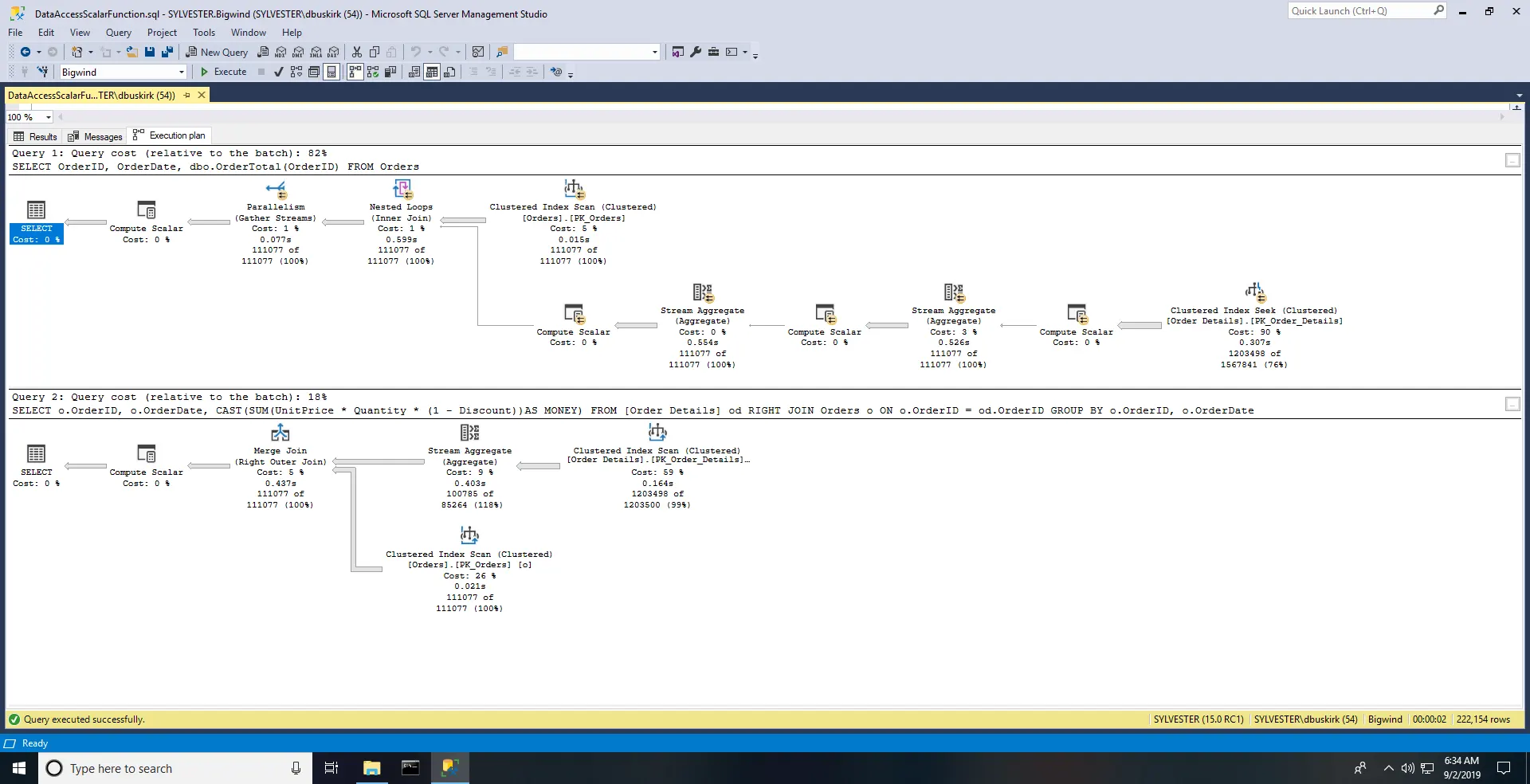
Repeated tests confirm that, on average, the traditional JOIN is still marginally better in this test.
Conclusion
Since the JOIN in this test is classic highly-optimized declarative code, it would be unreasonable to expect the UDF to perform better. But in his first contact with the world of production databases, Froid seems to have resolved a serious neurosis suffered by the query optimizer and has removed a major impediment to the practical use of scalar UDFs. Hopefully continued development of Froid technology will continue to yield benefits for code execution within functions and stored procedures.
