
It would be difficult for an R user not to have heard of GPU processing. In 2006, about seven years after it invented the GPU, Nvidia released the first incarnation of CUDA, the architecture that allowed scientists, engineers, and statisticians to use high-end graphics processors as pure floating-point number-crunchers.
Today, Nvidia's CUDA platform, specific for NVIVIA devices, has been joined by the cross-platform OpenCL development platform. But, as the uses of GPUs as general-purpose computing devices continues to grow, the question remains "What sort of problems benefit from GPU acceleration?" and perhaps more specifically "What's in it for me?"
For problems that involve multiple manipulations of large matrices, the answer is clear; use GPUs. Neural networks definitely fall into this category, and the deeper the better. But what about many of the routine tasks faced in R development. Will GPU processing help there as well?
gpuR
For illustrative purposes we will take a look at multiplying matrices using the gpuR package. There are many R packages that provide some degree of GPU support for R. Many, however, use GPU acceleration for particular algorithms but do not provide the R developer the opportunity to craft his or her own GPU code. As we shall see, this is entirely appropriate, since the biggest benefit provided by GPU code is achieved in large-scale highly-specialized algorithms.
Regardless of the algorithm or the R package used, a significant detriment to GPU processing is the time expended loading GPU code and data onto the hardware device. If we cannot achieve acceleration at least as great as this cost, the GPU is worthless.
In our example, we look at the multiplication of two matrices. We look at the processing of matrices of five different orders ranging from 1000 X 1000 to 5000 X 5000. We will also look at three ways multiplication might be handled for different tasks. The first is to multiply the matrices using only the cpu, as if the GPU were not even there. The second is to multiply the matrices on the GPU and retrieve the results. The last is to multiply the matrices on the GPU but not retrieve the results, which is what we would do if the output of the multiplication task was to be the input for another task on the GPU.
I would encourage you not to pay too much attention to the actual numbers, since these will change depending on your actual hardware and the precise algorithms involved. Our task here is simply to get an appreciation for how a GPU is most advantageously used.
The Results
Since we are looking at execution times, lower is better on this plot. The black line, labeled "gpuMatrix" represents sending a pair of matrices to the GPU, multiplying them, and retrieving the result. This is always the worst performer. The red line, representing classic processing on a classic cpu, was better than GPU processing until the order of the matrices exceeded 4000. This suggests that unless the matrices involved are extremely large (5000 X 5000 in this test) the improvement in matrix multiplication alone does not compensate for the time expended moving data onto the GPU.
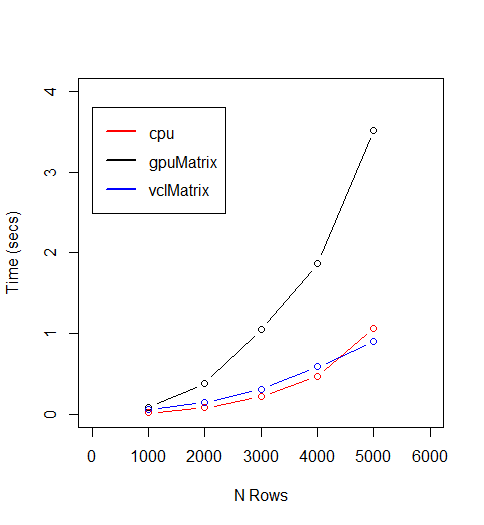
Conclusion
In the gpuR package, a vclMatrix remains on the GPU awaiting further processing. The more processing we can do on the GPU, the greater the chance we can earn back the time spent loading data onto the GPU device. Careful attention to coding details should be used to ensure that partial results are never read from the device into R only to be returned to the device a little later.
